len(get_FMD_img_paths('../_data/Confocal'))3000get_dataset_class (dataset_name)
regist_dataset (dataset_class)
get_FMD_img_paths (base_path)
len(get_FMD_img_paths('../_data/Confocal'))3000convert_setup_code (model_name)
convert_camera_code (model_name)
convert_sample_code (model_name)
TO DO: add code similar to next cell that can read info from metadata
parse_dir_name (dir_name)
Crop whole image into patches
crop (img, size, overlap)
preprocessing (data_path, patch_size=96, overlap=8, mode='NOISE_GEN', output_base_path='../_data/HDF5_confocal_s96_o08', train_noisegen_idx=[1], train_denoiser_idx=[2], train_all_idx=[1], test_idx=[19], overwrite=False)
| Type | Default | Details | |
|---|---|---|---|
| data_path | |||
| patch_size | int | 96 | |
| overlap | int | 8 | |
| mode | str | NOISE_GEN | [‘NOISE_GEN’, ‘DENOISER’, ‘ALL’] |
| output_base_path | str | ../_data/HDF5_confocal_s96_o08 | |
| train_noisegen_idx | list | [1] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18] |
| train_denoiser_idx | list | [2] | |
| train_all_idx | list | [1] | |
| test_idx | list | [19] | |
| overwrite | bool | False |
find_support_scene (img_paths, current_path)
load_and_display_hdf5_image (file_path, dataset_name='clean', patch_num=20, slice=0)
# Example usage:
output_base_path = '../_data/HDF5_confocal_s96_o08'
file_path = output_base_path + '/noise_gen/test/0500_19.hdf5'
print(file_path)
load_and_display_hdf5_image(file_path, dataset_name='clean', patch_num=1)../_data/HDF5_confocal_s96_o08/noise_gen/test/0500_19.hdf5
(1, 96, 96)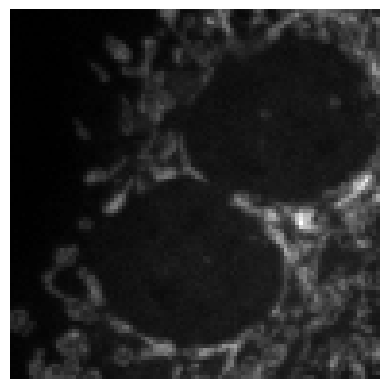
with h5py.File(file_path, 'r') as file:
image_data = file
print(list(image_data['config'].attrs.keys()))['camera', 'exposure-time', 'optical-setup', 'sample-code', 'scene-instance-number', 'scene-number', 'wavelength']BaseDataset (path=None, add_noise:str=None, crop_size:list=None, aug:list=None, n_repeat:int=1, n_data:int=None, ratio_data:float=None, step:int=None, scale=None)
An abstract class representing a :class:Dataset.
All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:__getitem__, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:__len__, which is expected to return the size of the dataset by many :class:~torch.utils.data.Sampler implementations and the default options of :class:~torch.utils.data.DataLoader. Subclasses could also optionally implement :meth:__getitems__, for speedup batched samples loading. This method accepts list of indices of samples of batch and returns list of samples.
.. note:: :class:~torch.utils.data.DataLoader by default constructs a index sampler that yields integral indices. To make it work with a map-style dataset with non-integral indices/keys, a custom sampler must be provided.
SIDD_benchmark (*args, **kwargs)
SIDD benchmark dataset class
SIDD_val (*args, **kwargs)
SIDD validation dataset class
SIDD_HDF (*args, **kwargs)
An abstract class representing a :class:Dataset.
All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:__getitem__, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:__len__, which is expected to return the size of the dataset by many :class:~torch.utils.data.Sampler implementations and the default options of :class:~torch.utils.data.DataLoader. Subclasses could also optionally implement :meth:__getitems__, for speedup batched samples loading. This method accepts list of indices of samples of batch and returns list of samples.
.. note:: :class:~torch.utils.data.DataLoader by default constructs a index sampler that yields integral indices. To make it work with a map-style dataset with non-integral indices/keys, a custom sampler must be provided.
dir_path = '../_data/HDF5_confocal_s96_o08/noise_gen/train/'
data = SIDD_HDF(dir_path, n_data=1, step=1)
data._load_data(0) 0%| | 0/150 [00:00<?, ?it/s]100%|██████████| 150/150 [00:58<00:00, 2.57it/s]{'clean': array([[[3., 3., 3., ..., 6., 6., 6.],
[3., 3., 3., ..., 6., 6., 6.],
[3., 3., 3., ..., 6., 6., 7.],
...,
[3., 3., 3., ..., 3., 3., 3.],
[3., 3., 3., ..., 3., 3., 3.],
[3., 3., 3., ..., 3., 3., 3.]]], dtype=float32),
'real_noisy': array([[[ 3., 3., 3., ..., 4., 4., 5.],
[ 3., 3., 3., ..., 6., 5., 7.],
[ 3., 3., 3., ..., 3., 10., 7.],
...,
[ 6., 3., 6., ..., 3., 3., 3.],
[ 3., 3., 3., ..., 3., 3., 3.],
[ 3., 3., 3., ..., 3., 3., 3.]]], dtype=float32),
'kwargs': {'camera': 2,
'exposure-time': 60,
'optical-setup': 1,
'sample-code': 0,
'scene-instance-number': 1,
'scene-number': 1,
'wavelength': 600}}data = SIDD_val(dir_path, n_data=1, step=1)
data._load_data(0)100%|██████████| 150/150 [00:18<00:00, 8.00it/s]{'clean': array([[[3., 3., 3., ..., 6., 6., 6.],
[3., 3., 3., ..., 6., 6., 6.],
[3., 3., 3., ..., 6., 6., 7.],
...,
[3., 3., 3., ..., 3., 3., 3.],
[3., 3., 3., ..., 3., 3., 3.],
[3., 3., 3., ..., 3., 3., 3.]]], dtype=float32),
'real_noisy': array([[[ 3., 3., 3., ..., 4., 4., 5.],
[ 3., 3., 3., ..., 6., 5., 7.],
[ 3., 3., 3., ..., 3., 10., 7.],
...,
[ 6., 3., 6., ..., 3., 3., 3.],
[ 3., 3., 3., ..., 3., 3., 3.],
[ 3., 3., 3., ..., 3., 3., 3.]]], dtype=float32)}